![[iOS] STT 구현하기(feat. Speech 프레임워크)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FozON7%2FbtsFlWSw3jp%2FAAAAAAAAAAAAAAAAAAAAAKX1Qb7NIQxXGoSMqucHn2odrQEk1itSvxhHuoTatf3S%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3D2dgoT7zkpFTjUyJAieYzk2PdJ2k%253D)
Speech 프레임워크
애플에서 기본적으로 제공하는 프레임워크
라이브 또는 사전 녹음된 오디오에서 음성 인식을 수행하고 텍스트 변환, 대체 해석 및 결과의 신뢰 수준을 수신한다.
SFSpeechRecognizer
음성 인식 서비스의 가용성을 확인하고 음성 인식 프로세스를 시작하는데 사용하는 개체
핵심적인 음성 인식을 수행한다.
SFSpeechAudioBufferRecognitionRequest
실제 디바이스 마이크의 오디오와 같이 캡처된 오디오 콘텐츠에서 음성을 인식하기 위한 요청을 하는 개체
SFSpeechRecognitionTask
음성 인식 진행 상황을 모니터링하기 위한 작업 개체
음성 인식 작업의 상태를 확인하거나, 중지, 취소 혹은 작업 종료 신호를 보낼 수 있다.
제약사항
iOS 13 이상만 지원한다.
애플 서버를 사용하기 때문에 꼭 “네트워크 연결”되어 있어야 한다.
1분이 지나면 자동으로 인식을 중지한다.
모든 언어가 지원되는 것은 아니다.
- 지원 언어 리스트
// 지원하는 언어 목록
let locales = SFSpeechRecognizer.supportedLocales()
// Output
[cs-CZ (fixed), da-DK (fixed), wuu-CN (fixed), de-DE (fixed), th-TH (fixed), en-ID (fixed), vi-VN (fixed), sk-SK (fixed), nl-BE (fixed), fr-CA (fixed), ca-ES (fixed), ro-RO (fixed), ms-MY (fixed), it-CH (fixed), uk-UA (fixed), fr-CH (fixed), tr-TR (fixed), en-SA (fixed), de-CH (fixed), hi-IN (fixed), zh-TW (fixed), en-ZA (fixed), nl-NL (fixed), es-CL (fixed), hu-HU (fixed), hr-HR (fixed), el-GR (fixed), ja-JP (fixed), en-AE (fixed), pt-PT (fixed), en-US (fixed), es-CO (fixed), hi-Latn (fixed), es-US (fixed), es-419 (fixed), yue-CN (fixed), en-CA (fixed), hi-IN-translit (fixed), en-IE (fixed), pt-BR (fixed), pl-PL (fixed), ru-RU (fixed), en-SG (fixed), de-AT (fixed), he-IL (fixed), en-GB (fixed), es-ES (fixed), sv-SE (fixed), id-ID (fixed), en-IN (fixed), it-IT (fixed), zh-HK (fixed), en-AU (fixed), ko-KR (fixed), fi-FI (fixed), zh-CN (fixed), fr-FR (fixed), es-MX (fixed), en-NZ (fixed), en-PH (fixed), ar-SA (fixed), fr-BE (fixed), nb-NO (fixed)]
구현하기
1. 권한 설정
- 음성 인식 사용 권한
"Privacy - Speech Recognition Usage Description"
- 마이크 사용 권한
"Privacy - Microphone Usage Description"
❗ 권한 설정 문구가 필요합니다.
// 권한 체크
private func checkPermissions() -> Observable<Bool> {
return Observable.combineLatest(
checkSpeechAuthorization(),
checkMicrophoneAuthorization()
) { speech, microphone in
return speech && microphone
}
}
// 음성 인식 권한 체크
private func checkSpeechAuthorization() -> Observable<Bool> {
return Observable.create { observer in
SFSpeechRecognizer.requestAuthorization { authStatus in
observer.onNext(authStatus == .authorized)
observer.onCompleted()
}
return Disposables.create()
}
}
// 마이크 권한 체크
private func checkMicrophoneAuthorization() -> Observable<Bool> {
return Observable.create { observer in
let audioSession = AVAudioSession.sharedInstance()
audioSession.requestRecordPermission { granted in
observer.onNext(granted)
observer.onCompleted()
}
return Disposables.create()
}
}2. 음성 인식 시작
// 음성 인식 시작
private func startRecognizing() {
// 이미 인식 중인 경우 더 이상 처리하지 않음
guard !isRecognizing else { return }
isRecognizing = true
// 오디오 엔진 및 인식 작업 초기화
stopAudioEngine()
cancelRecognitionTask()
// 오디오 세션 활성화 및 인식 요청 설정
guard activateAudioSession() else { return }
setupRecognitionRequest()
guard startRecognitionTask() else { return }
guard startAudioEngine() else { return }
}음성 인식을 시작하는 startRecognizing() 메서드입니다.
우선 이전의 오디오 작업을 취소합니다.
그 후, 오디오 세션을 활성화하고, 인식 요청을 설정하며, 인식 작업과 오디오 엔진을 시작하여 음성 인식을 준비합니다.
2-1. activateAudioSession():
private func activateAudioSession() -> Bool {
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
return true
} catch {
stopRecognizing()
updateAudioViewSubject.onNext(.error(error))
return false
}
}
이 메서드는 AVAudioSession을 활성화하는 역할을 합니다. AVAudioSession은 오디오 관련 작업을 관리하는 객체로, 이 메서드를 통해 오디오 세션을 설정합니다.
- setCategory(_:mode:options:): 오디오 세션의 카테고리를 설정합니다. 여기서는 .record 카테고리로 설정하여 오디오 입력을 가능하게 합니다. mode는 .measurement으로 설정되어 측정 모드로 설정되며, 이는 오디오 입력의 정확도를 높이는 데 도움이 됩니다. options는 .duckOthers로 설정되어 다른 오디오 출력을 줄이는 옵션을 사용합니다.
- setActive(_:options:): 오디오 세션을 활성화합니다. notifyOthersOnDeactivation 옵션은 오디오 세션이 비활성화될 때 다른 앱에 알림을 보내는 옵션입니다.
2-2. setupRecognitionRequest():
private func setupRecognitionRequest() {
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
recognitionRequest?.shouldReportPartialResults = true
}
이 메서드는 음성 인식에 필요한 요청을 설정하는 초기화 작업을 수행합니다.
- SFSpeechAudioBufferRecognitionRequest를 생성하여 recognitionRequest에 할당합니다. 이는 음성 인식에 사용될 요청 객체입니다.
- shouldReportPartialResults를 true로 설정하여, 부분적인 인식 결과를 실시간으로 트래킹 할 수 있도록 합니다.
2-3. startRecognitionTask():
private func startRecognitionTask() -> Bool {
guard let recognitionRequest = recognitionRequest else {
stopRecognizing()
return false
}
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { [weak self] result, error in
guard let self = self else { return }
guard self.isRecognizing else { return }
if let result = result {
let transcript = result.bestTranscription.formattedString
self.updateRecognizedTextRelay.accept(transcript)
self.stopNoAudioDurationTimer()
self.startNoAudioDurationTimer()
print(result.bestTranscription.formattedString)
}
if let error = error {
self.stopRecognizing()
self.updateAudioViewSubject.onNext(.error(error))
}
}
return true
}
이 메서드는 음성 인식 작업을 시작하고, 결과를 처리하여 인식된 텍스트를 업데이트합니다.
- speechRecognizer.recognitionTask(with:completion:)를 호출하여 음성 인식 작업을 시작합니다. 이 메서드는 인식 결과나 오류가 발생할 때마다 completion 핸들러를 호출합니다.
- completion 핸들러 내부에서는 결과가 있을 경우 인식된 텍스트를 업데이트하고, 오류가 발생한 경우에는 음성 인식을 중지하고 오류를 전달합니다.
2-4. startAudioEngine():
private func startAudioEngine() -> Bool {
let recordingFormat = audioEngine.inputNode.outputFormat(forBus: 0)
audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { [weak self] buffer, _ in
guard let self = self else { return }
recognitionRequest?.append(buffer)
self.processAudioData(buffer: buffer)
}
do {
try audioEngine.start()
return true
} catch {
stopRecognizing()
updateAudioViewSubject.onNext(.error(error))
return false
}
}이 메서드는 오디오 엔진을 시작하여 오디오 입력을 처리하고, 버퍼가 들어올 때마다 음성 인식 요청에 데이터를 추가합니다.
- 먼저, 입력 노드의 오디오 형식을 가져와서 recordingFormat에 할당합니다.
- installTap(onBus:bufferSize:format:block:)를 호출하여 입력 노드에 Tap을 설치합니다. Tap은 오디오 입력 버퍼에서 데이터를 가져오는 역할을 합니다. 여기서는 버퍼 사이즈와 형식을 설정하고, 클로저를 전달하여 버퍼가 들어올 때마다 실행되도록 합니다.
3. 음성 인식 중지
// 음성 인식 중지
private func stopRecognizing() {
// 타이머 및 오디오 엔진 중지, 인식 요청 및 작업 취소
stopNoAudioDurationTimer()
stopAudioEngine()
stopAudioSessionEngine()
stopRecognitionRequest()
cancelRecognitionTask()
isRecognizing = false
}
이 메서드는 타이머를 중지하고 오디오 엔진을 중지하며, 인식 요청과 작업을 취소하여 음성 인식을 종료합니다.
private func stopNoAudioDurationTimer() {
if noAudioDurationTimer != nil {
noAudioDurationTimer?.invalidate()
noAudioDurationTimer = nil
}
}
private func stopAudioSessionEngine() {
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setActive(false)
} catch {
print("Error occurred: \(error)")
}
}
private func stopAudioEngine() {
if audioEngine.isRunning {
audioEngine.stop()
audioEngine.inputNode.removeTap(onBus: 0)
}
}
private func stopRecognitionRequest() {
recognitionRequest?.endAudio()
recognitionRequest = nil
}
private func cancelRecognitionTask() {
recognitionTask?.cancel()
recognitionTask = nil
}4. 음성 인식 결과 업데이트
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { [weak self] result, error in
guard let self = self else { return }
guard self.isRecognizing else { return }
if let result = result {
let transcript = result.bestTranscription.formattedString
self.updateRecognizedTextRelay.accept(transcript)
self.stopNoAudioDurationTimer() // 타이머 중지
self.startNoAudioDurationTimer() // 타이머 시작
print(transcript) // 실시간 인식 결과
print(result.isFinal) // shouldReportPartialResults가 true면 항상 false 반환
}
if let error = error {
self.stopRecognizing()
self.updateAudioViewSubject.onNext(.error(error))
}
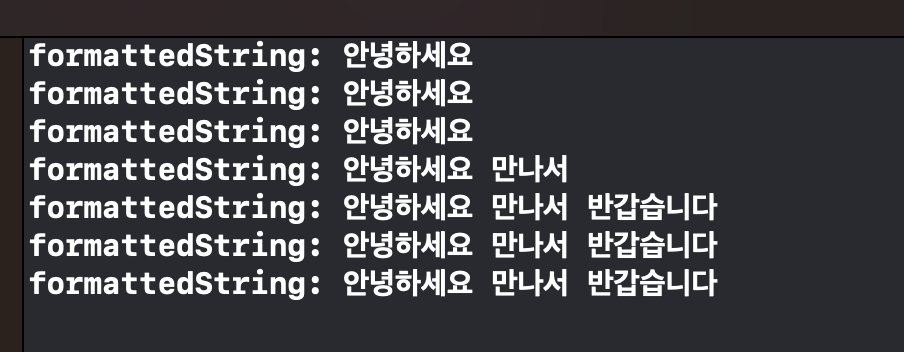
}recognitionTask는 비동기적으로 음성 입력을 처리하고 결과를 제공합니다.
결과가 제공되면 result 매개변수에 음성 인식 결과가 전달됩니다.
이를 통해 formattedString 속성을 사용하여 텍스트로 변환된 인식 결과를 얻을 수 있습니다.
SFSpeechRecognitionResult의 속성 중 하나인 isFinal은 음성 인식 결과가 최종적으로 완료되었는지를 나타냅니다.
2-2 처럼 shouldReportPartialResults 속성을 true로 설정하면, 실시간으로 부분적인 인식 결과를 제공하지만, 이 때 isFinal 값은 항상 false로 유지됩니다.
따라서, 음성 인식이 최종 완료되었음을 감지하기 위해서는 다른 방법을 사용해야 합니다.
필자는 사용자의 발화가 2초 동안 없을 경우 현재까지 인식된 결과를 반환하고 음성 인식을 중지하는 방식을 선택했습니다.
5. 음향 세기 표현
import Accelerate
audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { [weak self] buffer, _ in
guard let self = self else { return }
recognitionRequest?.append(buffer)
self.processAudioData(buffer: buffer)
}
private func processAudioData(buffer: AVAudioPCMBuffer) {
guard let channelData = buffer.floatChannelData?[0] else { return }
let frames = buffer.frameLength
let rmsValue = rms(data: channelData, frameLength: UInt(frames))
updateAudioVolumeViewSubject.onNext(CGFloat(rmsValue * 8 * 10))
print("RMS: \(rmsValue)")
}
private func rms(data: UnsafeMutablePointer<Float>, frameLength: UInt) -> Float {
var val: Float = 0
vDSP_measqv(data, 1, &val, frameLength)
val *= 1000
return val
}AVAudioEngine으로 부터 실시간으로 음향의 세기를 인식한 방법을 설명하겠습니다.
- processAudioData(buffer:) 메서드는 AVAudioPCMBuffer를 매개변수로 받습니다.
- 이 메서드 내에서는 주어진 버퍼에서 오디오 데이터를 추출합니다. 이 데이터는 오디오 신호의 강도를 나타냅니다.
- 추출된 오디오 데이터는 Accelerate 프레임워크의 vDSP_measqv 함수를 사용하여 RMS 값을 계산합니다.
- 계산된 RMS 값은 음향 크기를 나타내는데 사용됩니다.
필자는 RMS에 적당한 값을 곱하여 음향 세기 원의 지름으로 활용했습니다.

전체 코드
import Speech
import Accelerate
import RxSwift
import RxCocoa
final class SpeechRecognizer: NSObject, SFSpeechRecognizerDelegate {
private let disposeBag = DisposeBag()
private let speechRecognizer = SFSpeechRecognizer(locale: Locale.init(identifier: "ko-KR"))
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private var recognitionTask: SFSpeechRecognitionTask?
private let audioEngine = AVAudioEngine()
private var isRecognizing = false // 음성 인식 진행 중 상태를 추적하는 플래그
private var noAudioDurationTimer: Timer? // 음성 응답 타이머
private var noAudioDurationLimitSec: Int = 2 // 음성 응답이 해당 초동안 없으면 음성 중지
// Input
let requestRecognitionSubject = PublishSubject<SpeechRecognitionState>() // 음성 인식 시작 or 중지
// Output
let updateRecognizedTextRelay = BehaviorRelay<String>.init(value: "") // 인식된 텍스트 업데이트
let updateAudioViewSubject = PublishSubject<SpeechRecognitionOutput>() // 오디오뷰 업데이트
let updateAudioVolumeViewSubject = PublishSubject<CGFloat>() // 오디오버튼 볼륨 업데이트
override init() {
super.init()
speechRecognizer.delegate = self
bind()
}
private func bind() {
requestRecognitionSubject
.subscribe(with: self) { owner, recognizedState in
switch recognizedState {
case .recognizing:
owner.startRecognizing()
case .notRecognizing:
owner.stopRecognizing()
}
}
.disposed(by: disposeBag)
}
private func startRecognizing() {
guard !isRecognizing else { return }
isRecognizing = true
stopAudioEngine()
cancelRecognitionTask()
guard activateAudioSession() else { return }
setupRecognitionRequest()
guard startRecognitionTask() else { return }
guard startAudioEngine() else { return }
}
private func stopRecognizing() {
stopNoAudioDurationTimer()
stopAudioEngine()
stopRecognitionRequest()
cancelRecognitionTask()
isRecognizing = false
}
private func setupRecognitionRequest() {
recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
recognitionRequest?.shouldReportPartialResults = true
}
private func startRecognitionTask() -> Bool {
guard let recognitionRequest = recognitionRequest else {
stopRecognizing()
return false
}
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { [weak self] result, error in
guard let self = self else { return }
guard self.isRecognizing else { return }
if let result = result {
let transcript = result.bestTranscription.formattedString
self.updateRecognizedTextRelay.accept(transcript)
self.stopNoAudioDurationTimer()
self.startNoAudioDurationTimer()
print(result.bestTranscription.formattedString)
}
if let error = error {
self.stopRecognizing()
self.updateAudioViewSubject.onNext(.error(error))
}
}
return true
}
private func stopRecognitionRequest() {
recognitionRequest?.endAudio()
recognitionRequest = nil
}
private func cancelRecognitionTask() {
recognitionTask?.cancel()
recognitionTask = nil
}
private func activateAudioSession() -> Bool {
let audioSession = AVAudioSession.sharedInstance()
do {
try audioSession.setCategory(.record, mode: .measurement, options: .duckOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
return true
} catch {
stopRecognizing()
updateAudioViewSubject.onNext(.error(error))
return false
}
}
private func startAudioEngine() -> Bool {
let recordingFormat = audioEngine.inputNode.outputFormat(forBus: 0)
audioEngine.inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { [weak self] buffer, _ in
guard let self = self else { return }
recognitionRequest?.append(buffer)
self.processAudioData(buffer: buffer)
}
do {
try audioEngine.start()
return true
} catch {
stopRecognizing()
updateAudioViewSubject.onNext(.error(error))
return false
}
}
private func stopAudioEngine() {
if audioEngine.isRunning {
audioEngine.stop()
audioEngine.inputNode.removeTap(onBus: 0)
}
}
private func startNoAudioDurationTimer() {
noAudioDurationTimer = Timer.scheduledTimer(
timeInterval: TimeInterval(self.noAudioDurationLimitSec),
target: self,
selector:#selector(timeOut),
userInfo: nil,
repeats: false
)
}
private func stopNoAudioDurationTimer() {
if noAudioDurationTimer != nil {
noAudioDurationTimer?.invalidate()
noAudioDurationTimer = nil
}
}
@objc private func timeOut() {
stopRecognizing()
let recognizedText = updateRecognizedTextRelay.value
updateAudioViewSubject.onNext(.success(recognizedText))
}
private func rms(data: UnsafeMutablePointer<Float>, frameLength: UInt) -> Float {
var val: Float = 0
vDSP_measqv(data, 1, &val, frameLength)
val *= 1000
return val
}
private func processAudioData(buffer: AVAudioPCMBuffer) {
guard let channelData = buffer.floatChannelData?[0] else { return }
let frames = buffer.frameLength
let rmsValue = rms(data: channelData, frameLength: UInt(frames))
updateAudioVolumeViewSubject.onNext(CGFloat(rmsValue * 8 * 10))
print("RMS: \(rmsValue)")
}
}
enum SpeechRecognitionState {
case recognizing // 인식 중
case notRecognizing // 인식 중이 아님
}
enum SpeechRecognitionOutput {
case success(String) // 인식 성공
case error(Error) // 인식 실패
}
참고자료
Speech | Apple Developer Documentation
Speech | Apple Developer Documentation
Perform speech recognition on live or prerecorded audio, and receive transcriptions, alternative interpretations, and confidence levels of the results.
developer.apple.com
'iOS' 카테고리의 다른 글
| [iOS] Static Widget 만들기 (2) | 2024.03.04 |
|---|---|
| [iOS] iOS 캡쳐 방지 기술 (3) | 2022.11.01 |
| [iOS] 클로저에서 [weak self] 알아보기 (0) | 2022.07.27 |
| [iOS] APN, FCM 정리 (0) | 2022.07.25 |
| [iOS] UIStackView 정리 (0) | 2022.07.12 |